0 محصولات
نمایش سبد خرید

هرآنچه باید درباره هستههای تنسور بدانید

هستههای تنسور قطعات کوچکی هستند که میتوانند انجام فعالیتهای پردازشی بسیار سنگین و پیچیده را برای کارتهای گرافیک آسانتر کنند. این هستهها میتوانند برای افزایش وضوح جزئیات و رزولوشن تصاویر بازیها نیز به کارت گرافیک کمک کنند.
انویدیا در چهار سال اخیر کارتهای گرافیکی متفاوتی را عرضه کرده که علاوه بر هستههای معمولی که در اختیار شیدرها (سایهزنها در صحنههای سهبعدی) قرار میگیرند، هستههای دیگری نیز دارند که تحت عنوان تنسور (Tensor) شناخته میشوند. این هستههای مرموز در دستگاههای مختلفی از جمله کامپیوترهای دسکتاپ، لپتاپها، ورکاستیشنها و حتی پایگاههای داده در سراسر جهان مورداستفاده قرار میگیرند؛ اما هستههای تنسور چه هستند و چه کاربردی دارند و آیا واقعا وجود آنها در کارت گرافیک ضروری است یا خیر؟ در این مقاله شما را با ساختار هسته تنسور آشنا میکنیم و در مورد نحوه استفاده از هستههای تنسور در دنیای گرافیک و یادگیری عمیق نیز توضیح میدهیم.
مفاهیم ریاضی تشکیلدهنده اساس ساختار هستههای تنسور
برای فهم بهتر عملکرد هستههای تنسور و کاربردهای این هستهها ابتدا باید با یک سری از مفاهیم ریاضی که هستههای تنسور بر مبنای آنها شکل گرفتهاند، آشنا شویم. تمام ریزپردازندهها با هر نوع عملکردی عملیات پردازشی را با استفاده از انجام چهار عمل ریاضی اصلی (جمع، تفریق و غیره) روی اعداد انجام میدهند.
گاهی اوقات این اعداد باید دستهبندی شوند، چون ارتباط خاصی با یکدیگر دارند؛ بهعنوان مثال زمانی که تراشهای در حال پردازش دادهها برای رندر گرافیکی است، شاید برای عامل مقیاس به اعداد صحیح نیاز داشته باشد (اعدادی مثل +۲ و +۱۱۵)؛ اما برای دست یافتن به مختصات در فضای سهبعدی با اعداد اعشاری کار میکند (مثل اعدادی +۰.۱، -۰.۵، +۰.۶). در مورد دوم برای موقعیتیابی به سه مجموعه داده نیاز داریم. در کل میتوانیم بگوییم نزدیک تنسور شیء ریاضیاتی است که بین دو شیء ریاضی که با یکدیگر ارتباط دارند، رابطه برقرار میکند. هستههای تنسور معمولا به شکل آرایهای از اعداد نمایش داده میشوند. این آرایه با تعداد ابعاد مختلف میتواند به شکل زیر نمایش داده شود.

همانطور که در شکل بالا میبینید، آرایه اعداد هستههای تنسور در سادهترین حالت میتواند بدون هیچ بعدی نمایش داده شود و در این حالت تنها یک مقدار دارد. نام دیگر چنین هسته تنسوری، اسکالر (عددی) است. با افزایش بعدها ساختارهای متداول ریاضی دیگری را میبینیم که شامل موارد زیر میشود:
- تنسور یک بعدی: برداری
- تنسور دو بعدی: ماتریسی
به بیان ساده هر تنسور اسکالر دربردارنده ساختار 0x0، تنسور برداری دربردارنده ساختار ۱x0، تنسور ماتریسی دربردارنده ساختار ۱x1است. ما برای آسانتر کردن فهم این مفاهیم و مربوط کردن آنها به هستههای تنسور مورد استفاده در کارتهای گرافیک، تنها در مورد تنسورهایی که در قالب ماتریس مورد استفاده قرار میگیرند، توضیح میدهیم. عمل ضرب یکی از مهمترین انواع عملیات ریاضی متداول با ماتریسهاست. اجازه دهید ببینیم چگونه دو ماتریس متشکل از چهار ردیف و چهار ستون در یکدیگر ضرب میشوند.

جواب نهایی ضرب ماتریسها برابر با تعداد سطر در ماتریس اول و تعداد ستون در ماتریس دوم است. بنابراین چگونه باید این ماتریسها را در یکدیگر ضرب کرد. راهحل انجام این کار در عکس زیر به تصویر کشیده شده است:
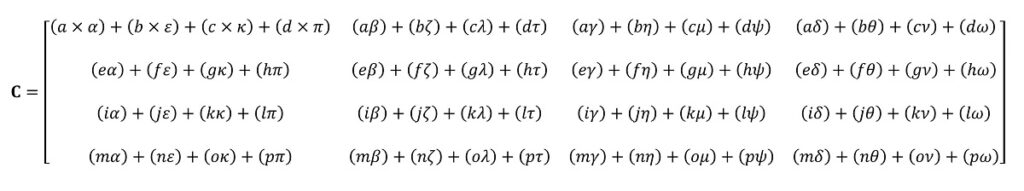
همانطور که میبینید برای ضرب دو ماتریس ساده در یکدیگر، عملیات ضرب و تقسیم زیادی انجام شده است. به دلیل اینکه امروزه هر پردازندهای (CPU) میتواند این عملیات را انجام دهد؛ بنابراین هر دستگاه دارای پردازنده مرکزی از جمله تمام کامپیوترهای دسکتاپ و لپتاپها و حتی تبلتها میتوانند در زمینه مدیریت تنسورهای ساده کاملا موفق عمل کنند و وظیفه محاسبه آنها را برعهده گیرند.
بههرحال در مثال بالا ۶۴ عملیات ضرب و ۴۸ عملیات جمع اضافه شده. نتیجه هر ضرب کوچک عددی کوچک است که باید در فضایی نگهداری شود و پس از آن با جواب ضرب بعدی جمع شود. در نهایت تمام اعداد بهدستآمده باید به تنسور نهایی تبدیل شوند که این تنسور هم در فضایی ذخیره میشود. اگرچه از دیدگاه علم ریاضی ضرب ماتریسی ساده است؛ اما از لحاظ پردازشی فعالیت سنگینی به شمار میرود. انجام این عمل ضرب مستلزم ساخت و ذخیرهسازی تعداد زیادی عدد است و حافظه کش پردازنده باید اطلاعات زیادی را بخواند و بنویسد.

در سالهای اخیر افزونههای متنوعی در پردازندههای AMD و اینتل ایجاد شدهاند که امکان مدیریت و محاسبه تعداد زیادی از اعداد اعشاری بهصورت همزمان را برای این پردازندهها فراهم کردهاند. از میان این افزونهها میتوان به MMX ،SSE و در حال حاضر AVX اشاره کرد. تمام این افزونهها جزو گروه SIMD یا «یک دستورالعمل برای تمام دادهها» محسوب میشوند.
این افزونهها تنها چیزی هستند که ما برای ضرب ماتریسها به آن نیاز داریم؛ اما امروزه پردازندههایی بهصورت اختصاصی برای انجام عملیات مرتبط با وظایف SIMD طراحی شدهاند. این پردازندهها امروزه بهعنوان پردازنده گرافیکی یا GPU در سیستمها مورد استفاده قرار میگیرند.
پردازندهای بسیار هوشمندتر از ماشینحساب معمولی
در دنیای پردازش گرافیکی باید مجموعه گستردهای از دادهها در آن واحد منتقل و همزمان در قالب برداری پردازش شود. پردازندههای گرافیکی با برخورداری از قابلیت پردازش موازی برای مدیریت تنسورها، پردازندههای کاملا ایدهآلی هستند و تمام پردازندههای گرافیکی جدید از مفهوم جدیدی تحت عنوان GEMM یا General Matrix Multiplication پشتیبانی میکنند.
در این عملیات دو ماتریس در یکدیگر ضرب و جواب ضرب با ماتریس دیگری جمع میشود؛ البته در مورد فرمتی که باید توسط ماتریسها مورداستفاده قرار گیرد تعداد سطرها و ستونهای هر یک از ماتریسها محدودیتهایی وجود دارد که در تصویر زیر مشاهده میکنید:
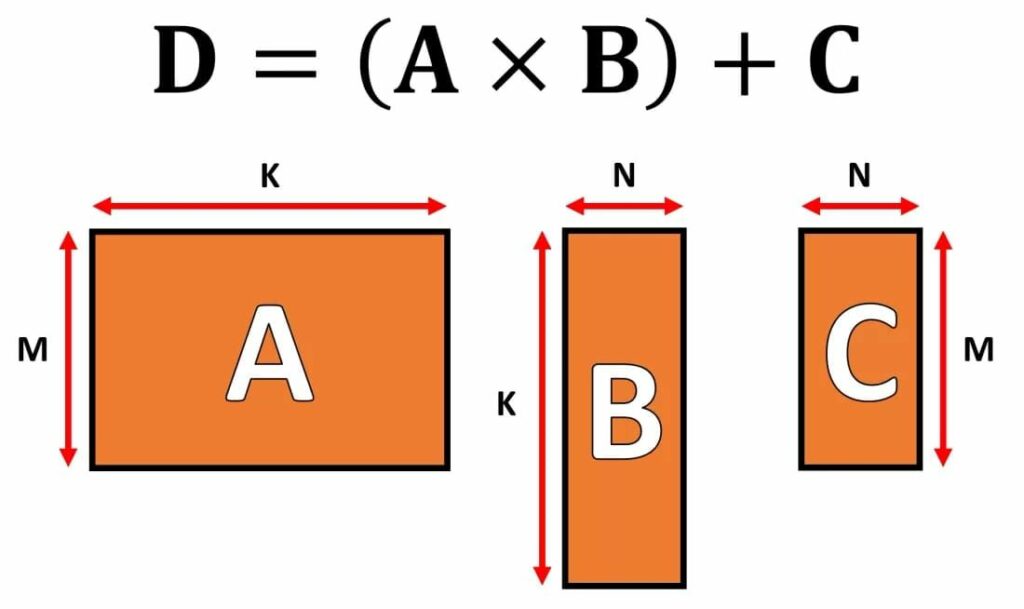
به نظر میرسد الگوریتمهای مورد استفاده برای انجام عملیات مرتبط با ماتریسها، زمانی که ماتریسها مربعی هستند، بهترین عملکرد را دارند (بهعنوانمثال در صورت استفاده از ماتریسی با آرایه ۱۰X10 در مقایسه با زمانی که از ماتریسی با آرایه ۵۰X2 استفاده شود، نتیجه بهتری حاصل میشود؛ اما درصورتیکه سیستم برای پردازش این محاسبات، سختافزار اختصاصی در اختیار داشته باشد، این الگوریتمها هنوز هم خوب عمل میکنند.)
انویدیا در دسامبر سال ۲۰۱۷ یک کارت گرافیک مجهز به پردازنده گرافیکی با معماری جدیدی تحت عنوان ولتا (Volta) وارد بازار کرده بود که برای گیمرهای حرفهای طراحی شده بود و تا پیش از این هیچ یک از کارتهای گرافیک جیفورس مجهز به این تراشه نبودند.
کارت گرافیک جدید انویدیا به دلیل اینکه نخستین کارت گرافیک مجهز به هستههای مختص انجام محاسبات تنسور بود، کارت گرافیک خاص و منحصربهفردی بود. در زمان عرضه این کارت گرافیک هیچ کس نحوه کار آن را نمیدانست. هستههای تنسور این کارت گرافیک انویدیا برای انجام ۶۴ عملیات GEMM در هر چرخه کلاک روی ماتریس ۴X4 طراحی شده بود. این هستهها دربردارنده مقادیر FP16 (اعداد اعشاری با سایز ۱۶ بیتی) هستند. بهعبارت دیگر تنسورها قابلیت ضرب FB16 با جمع FB32 را دارند. اندازه چنین تنسورهایی واقعا کوچک است؛ بنابراین زمانی که دیتاسنترها را با اندازه واقعی پردازش میکنند، هستهها در میان بلوکهای کوچک ماتریسهای بزرگتر تقسیم میشوند تا بهتدریج به پاسخ نهایی برسند.
نزدیک به دو سال پیش انویدیا از معماری تورینگ (Turing) رونمایی کرد. این بار هستههای تنسور به کارتهای گرافیک مورد استفاده توسط کاربران عادی نیز راه پیدا کرد. این سیستم به گونهای بهروزرسانی شده که شکل دیگری از دادهها را نیز پشتیبانی میکند که از میان آنها میتوان به INT8 یا اعداد صحیح ۸ بیتی اشاره کرد؛ البته تنها تفاوت معماری تورینگ با معماری ولتا، همین بهروزرسانیهاست و تفاوت دیگری با یکدیگر ندارند.

انویدیا در ابتدای سال میلادی گذشته معماری امپر (Ampere) را برای نخستین بار در کارت گرافیک A100 که برای استفاده در دیتاسنترها طراحی شده، به کار گرفت و اینبار انویدیا عملکرد کارت گرافیک خود را به میزان بسیار زیادی بهبود داد (تعداد عملیات GEMM در هر چرخه از ۶۴ عملیات به ۲۵۶ عملیات افزایش یافت) و این کارت گرافیک از فرمت دادههای بیشتری نیز پشتیبانی میکند. در ضمن در این کارتهای گرافیک توانایی پردازش و مدیریت سریع تنسورهای کمپشت (تنسورهایی که تعداد ارقام صفر آنها زیاد است) نیز اضافه شد.

برنامهنویسان میتوانند به هستههای تنسور در کارتهای گرافیک دارای معماری تورینگ، ولتا و امپر بهراحتی دسترسی پیدا کنند. کد برنامه باید با استفاده از یک نشان یا فلگ (Flag) به واسط برنامهنویسی کاربردی (API) و درایورها این پیام را بدهند که یرنامهنویس میخواهد از هستههای تنسور استفاده کند؛ البته نوع داده لزوما باید از انواع دادههای قابل پشتیبانی توسط هسته باشد و ابعاد ماتریسها نیز باید یکی از مضربهای عدد ۸ باشد. در صورت ایجاد شدن تمام شرایط، انجام کارهای دیگر برعهده سختافزار خواهد بود.
با تمام این تفاسیر به نظر میرسد که هستههای تنسور عملکرد مناسبی دارند؛ اما شاید از خود بپرسید این هستهها در انجام عملیات GEMM تا چه اندازه بهتر از هستههای معمولی پردازنده گرافیکی عمل میکنند؟
زمانی که نخستین کارت گرافیک با معماری ولتا عرضه شد، آزمایشی ریاضی توسط وبسایت Anadtech انجام شد که با استفاده از ۳ کارت گرافیک متفاوت انویدیا که شامل یک کارت گرافیک با معماری ولتا، یک کارت مبتنی بر معماری پاسکال و یک کارت گرافیک قدیمیتر مبتنی بر معماری مکسول (Maxwell) صورت پذیرفت.
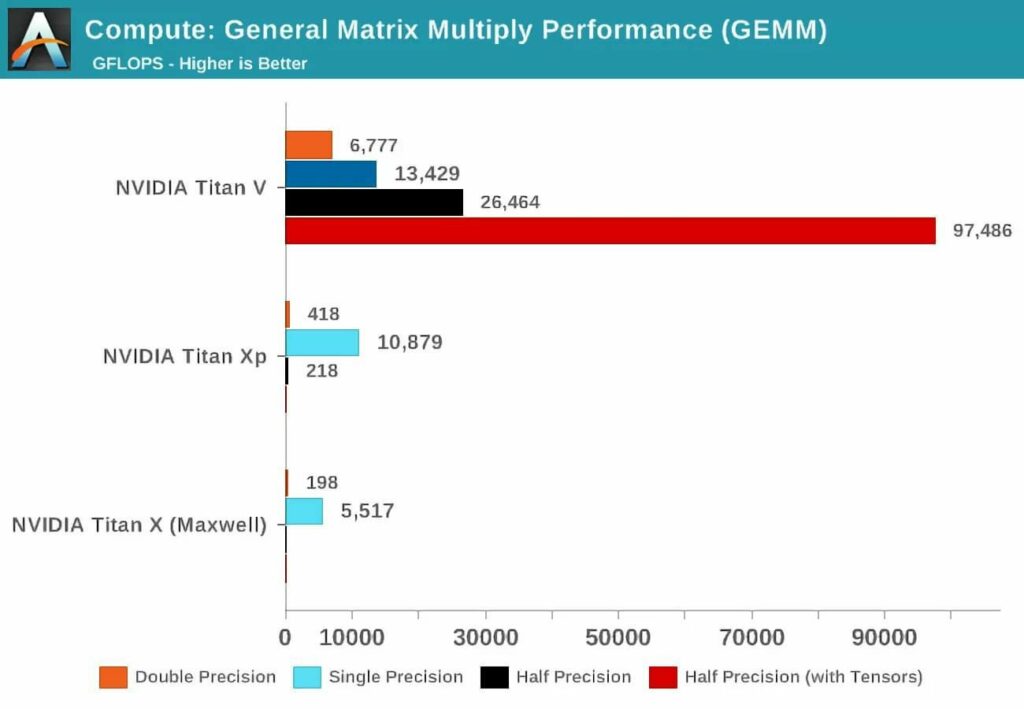
مفهوم Precision به تعداد بیتهای مورد استفاده برای اعداد اعشاری در ماتریسها اشاره میکند. کلمه Double به ۶۴ بیت، کلمه Single به ۳۲ بیت و کلمه Half به ۱۶ بیت اشاره دارد. محور افقی نشانگر حداکثر عملیات اعشاری قابل انجام در هر ثانیه است که بهصورت اختصاری با مفهوم فلاپس (FLOPs) نمایش داده میشود (به خاطر داشته باشید هر عملیات GEMM معادل ۳ فلاپس است).
با یک نگاه به نتایج زمانی که بهجای هستههای معمولی که هستههای کودا (CUDA) نیز نامیده میشوند، از هستههای تنسور استفاده شده است، بهخوبی متوجه میشویم که هستههای تنسور برای انجام محاسبات پیچیده ریاضی عملکرد موفقتری دارند. اکنونکه با ساختار هستههای تنسور آشنا شدیم، اجازه دهید ببینیم این هستهها چه کاربردی دارند.
کاربردهای هستههای تنسور
استفاده از ریاضی تنسور میتواند در حوزه فیزیک و مهندسی دستاوردهای زیادی را به ارمغان بیاورد. درضمن این شاخه از علم ریاضی در حل مشکلات بسیار پیچیده حوزه مکانیک سیالات، الکترومغناطیس و فیزیک نجومی مورد استفاده قرار میگیرد. البته همیشه کامپیوترهایی که برای پردازش این نوع از اعداد مورد استفاده قرار میگیرند، عملیات ماتریس را با استفاده از مجموعه عظیمی از پردازندهها (سیپییوها) انجام میدهند.
در حوزه یادگیری ماشینی نیز به میزان زیاد تواناییهای بالقوه ریاضی تنسور استفاده میشود؛ مخصوصا در حیطه یادگیری عمیق. در تمام این حوزهها مجموعهای عظیم از دادهها در آرایههای متعددی که شبکه عصبی نام دارند، مدیریت میشوند. در این مفاهیم به ارتباطات بین مقادیر مختلف دادهها وزن خاصی داده میشود که نشاندهنده اهمیت زیاد این ارتباط است.
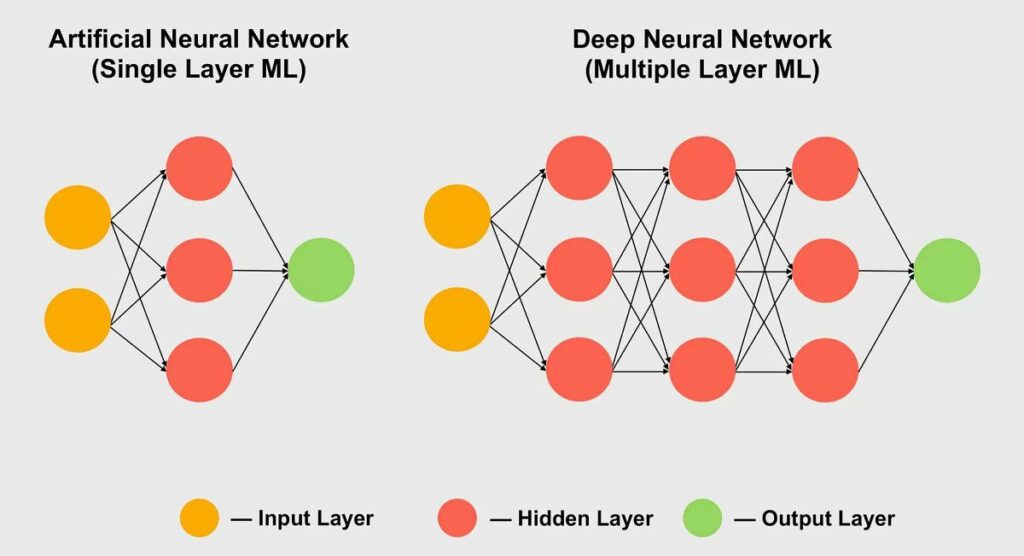
در این ساختار زمانی که میخواهید بدانید این ارتباطات را که تعداد آنها به صدها یا هزاران ارتباط میرسد، چگونه با هم تعامل دارند، باید هر تکه از داده موجود در شبکه را با وزنهای متفاوت وزن دادهها ضرب کنید. بهعبارتدیگر این محاسبه همان ضرب دو ماتریس است که در ریاضی کلاسیک تنسور انجام میشود.
به همین دلیل در تمام ابرکامپیوترهای مورد استفاده برای بهرهمندی از قابلیتهای یادگیری عمیق از پردازنده گرافیکی استفاده میشود که تمام آنها توسط انویدیا ساخته شدهاند. لازم به ذکر است؛ بسیاری از شرکتهای مطرح در حال ساخت پردازندههای تنسور اختصاصی خود هستند؛ بهعنوانمثال گوگل خبر ساخت نخستین TPU یا همان پردازنده تنسور را در سال ۲۰۱۶ اعلام کرد؛ البته این پردازندهها بسیار خاص هستند و بهجز انجام عملیات ماتریس کار دیگری نمیتواند انجام دهد.

هستههای تنسور در کارتهای گرافیک
اکنونکه با ساختار و کاربردهای هفتههای تنسور آشنا شدهاید. به نظر شما این هستهها در کارتهای گرافیک چه استفادهای میتواند داشته باشد و یا اینکه آیا کاربری که در حوزه فیزیک اختری فعالیت نمیکند و با حل مسئلههای مرتبط با منیفلد ریمانی کاری ندارد یا آزمایشهای مرتبط با سطوح مختلف شبکه عصبی پیچشی را انجام نمیدهد، واقعا به هستههای تنسور نیاز دارد؟ وجود هستههای تنسور در کارتهای گرافیک برای انجام وظایف متداول این کارتها مانند رندر گرافیکی و رمزگذاری و رمزگشایی ویدیوها لازم نیست و اگر برای چنین کارهایی میخواهید کارت گرافیک تنسور بخرید، عملا میخواهید پولتان را هدر دهید. با این وجود انویدیا در سال ۲۰۱۸ کارت گرافیک Turing GeForce RTX را با هستههای تنسور تولید کرد و در کنار آن قابلیت DLSS یا همان Deep Learning Super Sampling را معرفی کرد (این فناوری برای ارتقای موقتی وضوح تصاویر با استفاده از فناوری یادگیری عمیق کاربرد دارد).

اگر بخواهیم بهطور ساده هدف از استفاده از هستههای تنسور و فناوری DLSS را در کارتهای گرافیک جدید انویدیا بیان کنیم، باید بگوییم که انویدیا با عرضه کارت گرافیک فریمی را در ررزولوشن پایین رندر میکند و زمانی که رندر پایان یابد، رزولوشن تصویر افزایش پیدا میکند و ابعاد آن به ابعاد مانیتور میرسد (بهعنوانمثال میتوان با استفاده از کارتهای گرافیک جدید فریمی را در رزولوشن ۱۰۸۰p رندر کرد و سپس ابعاد آن را به ۱۴۴۰pتغییر داد). با استفاده از این روش میتوان حتی در مواردی که تصویر دارای رزولوشن و پیکسلهای کمی است، تصویری با وضوح بالا ببینید.
کنسولها سالهاست که از چنین رویکردی برای افزایش وضوح تصاویر استفاده میکنند و تعداد زیادی از کامپیوترهای گیمینگ امروزی نیز از این قابلیت برخوردارند.
در تصویر زیر که از بازی Assassin’s Creed: Odyssey ساخت شرکت یوبیسافت انتخاب شده، رزولوشن رندر را میتوان تنها تا ۵۰ درصد رزولوشن مانیتور کاهش دهیم که متاسفانه نتیجه چندان خوبی ندارد. در این تصاویر میتوانید صحنهای از بازی با رزولوشن ۴K با حداکثر تنظیمات گرافیکی را مشاهده کنید.

زمانی که رزولوشن بازی بالا باشد، بافتها بسیار بهتر به نظر میرسند و جزئیات بازی وضوح بسیار بیشتری پیدا میکنند. متاسفانه پردازش تمام پیکسلها که تعداد آنها واقعا زیاد است، عملیات پردازشی گستردهای را میطلبد. در تصویر زیر بازی در رزولوشن 1080p رندر شده است و تعداد پیکسلها در این عملیات پردازشی تنها ۲۵ درصد عملیات پردازشی قبلی است؛ اما در پایان پردازش از هستههای سایهزن نیز استفاده شده تا رزولوشن تصویر به ۴K برسد.

تفاوت این دو تصویر که به دو شکل کاملا متفاوت پردازش شدهاند، در نگاه اول مشخص نیست؛ چون تصویر با فرمت JPEG فشرده شده و روی وبسایت بارگذاری شده که کیفیت آن را کاهش میدهد؛ اما در تصویر دوم جزئیاتی مانند سلاح شخصیت بازی و شکل صخرهها در عمق تصویر کمی تار شدهاند. در تصویر زیر بخشی از تصویر زوم و کراپ شده است که اگر بهدقت به این تصاویر نگاه کنیم، بهتر متوجه این تفاوتها میشویم.

تصویر سمت چپ با رزولوشن ۴K رندر شده؛ اما تصویر دوم با رزولوشن ۱۰۸۰P رندر شده و پس از آن به رزولوشن ۴K ارتقا داده شده است. تفاوت این دو تصویر زمانی بیشتر مشهود میشود که تصویر حرکت کند. در چنین حالاتی در تصویر دوم جزئیات کاهش مییابد و تار میشود؛ البته میتوان با کمک ایجاد جلوههای افزایش وضوح (شارپنینگ) که توسط کارت گرافیک انجام میشود، بخشی از جزئیات را برگرداند؛ اما استفاده از چنین قابلیتی چندان منطقی نیست.
در چنین مواقعی قابلیت DLSS وارد عمل میشود. پس از عرضه نخستین کارتهای گرافیک انویدیا دارای این قابلیت، چند بازی هم با رزولوشن بالا و هم با رزولوشن پایین با استفاده از تکنیک Anti-Aliasing (تکنیکی برای صاف کردن لبه و سطح سطوح) و هم بدون استفاده از این قابلیت اجرا شدند. در تمام این حالات خروجی کاملا مطلوب بود و تصاویر خوبی ایجاد شدند. این تصاویر در ابرکامپیوترها بارگذاری شدند که تمام آنها از شبکههای عصبی برای یافتن بهترین روش ممکن برای تبدیل تصویر ۱۰۸۰p به تصویری با رزولوشن بالاتر استفاده میکردند.

فناوری DLSS 1.0 عملکرد چندان خوبی نداشت زیرا در هنگام استفاده از آن جزئیات یا از بین میرفتند یا لرزش آزاردهندهای داشتند. در ضمن این فناوری بهطور کامل از هستههای تنسور استفاده نمیکرد و برای ارتقای جزئیات از شبکه متعلق به انویدیا استفاده میکرد و هر یک از بازیهایی که از DLSS پشتیبانی میکنند باید بهصورت اختصاصی توسط شبکه انویدیا مورد بررسی قرار بگیرند تا الگوریتم اختصاصی هر یک از آنها برای ارتقای وضوح تصویر آنها ایجاد شود.
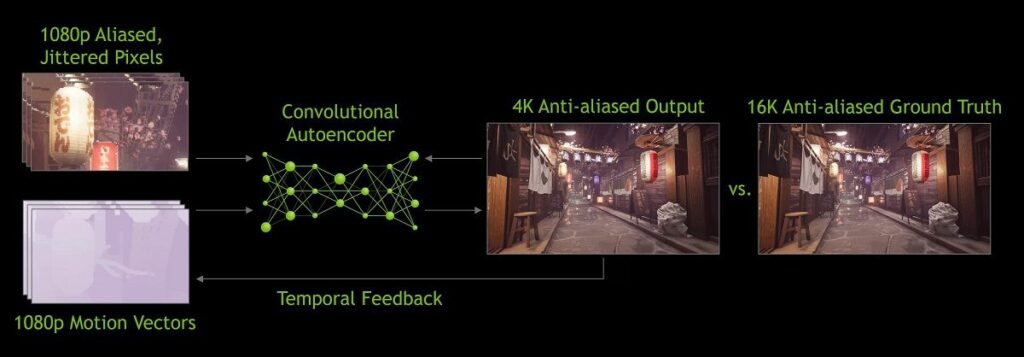
در سال ۲۰۲۰ نسخه ۲.۰ DLSS عرضه شد که نسبت به قبل به میزان قابلتوجهی بهبود یافته بود. یکی از پیشرفتهای قابلتوجه این نسخه نسبت به قبل این است که ابرکامپیوترهای انویدیا تنها برای ایجاد الگوریتمهای عمومی ارتقای وضوح تصویر مورد استفاده قرار میگرفتند؛ اما در نسخه جدید DLSS دادههای بهدستآمده از فریم رندر شده، با استفاده از مدل عصبی برای پردازش پیکسلها مورد استفاده قرار میگیرد و برای انجام این کار از هستههای تنسور پردازندههای گرافیکی کمک میگیرد.

DLSS 2.0 تواناییهای بالقوه زیادی دارد که بدون شک در آینده مشخص میشود؛ اما در حال حاضر تعداد کمی از بازیها از آن پشتیبانی میکنند بسیاری از توسعهدهندگان به دنبال بهرهمندی از تواناییهای این قابلیت در بازیهای آینده هستند. مطمئنا DLSS در حوزه ارتقای وضوح تصاویر تحولات گستردهای را ایجاد خواهد کرد و سرمایهگذاری برای تکامل این قابلیت واقعا ارزش دارد.
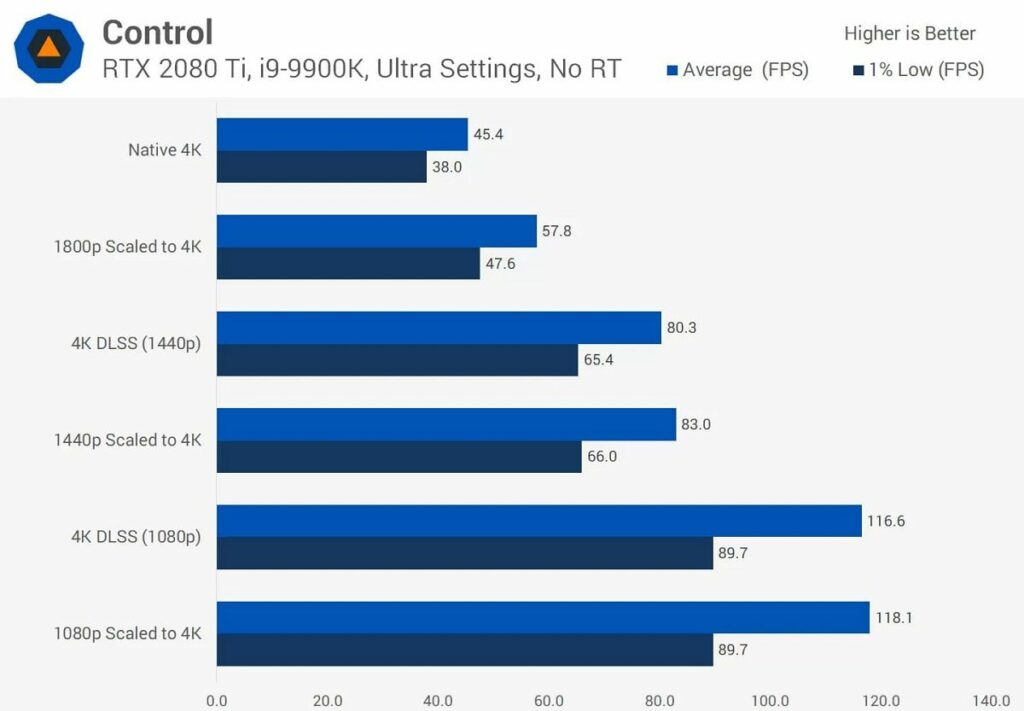
اگرچه نتیجه بصری قابلیت DLSS همیشه عالی و بینقص نیست؛ اما با افزایش توانایی رندرینگ این امکان را برای توسعهدهندگان فراهم میکند که بتوانند از جلوههای بصری بیشتری استفاده کنند و بازیهای دارای گرافیک یکسان را برای پلتفرمهای بیشتری ایجاد کنند.
در اغلب موارد قابلیت DLSS به همراه قابلیتهای مرتبط با رهگیری پرتو یا Ray tracing (قابلیتهایی که برای افزایش دقت نوردهی و ایجاد سایهها به شکل بهتر به کار گرفته میشوند) در بازیهایی که از این قابلیت پشتیبانی میکنند، به میزان زیادی مورد توجه قرار گرفته است.
پردازندههای گرافیکی سری جیفورس علاوه بر هستههای معمولی، دارای واحدهای پردازشی جدیدی تحت عنوان هستههای RT هستند. واحدهای منطقی اختصاصی برای سرعت بخشیدن به پردازشهای Ray triangle و انجام محاسبات مربوط به BVH (اجسام هندسی گروهبندیشده مرتبط با یکدیگر) استفاده میشوند.
انجام این فرآیندها که با هدف تشخیص نقطه تماس نور با سایر اجسام فرآیندها موجود در صحنه صورت میپذیرد، فرآیند بسیار زمانبری است.
انجام محاسبات مربوط به رهگیری پرتو فعالیت بسیار پیچیدهای است؛ بنابراین توسعهدهندگان باید برای پیادهسازی قابلیت رهگیری پرتو در بازیها، تعداد پرتوهای نور و همچنین حرکت نور در نقاط مختلف صحنه را محدود کنند.
از سوی دیگر انجام این کار نیز ممکن است باعث ایجاد نویز در تصویر شود و تصویر کمی برفکی به نظر برسد. به همین دلیل استفاده از یک الگوریتم حذف نویز ضرورت پیدا میکند که باعث پیچیدهتر شدن محاسبات میشود. ممکن است هستههای تنسور برای بهبود عملکرد الگوریتمهای حذف نویز که بر پایه استفاده از هوش مصنوعی طراحی شدهاند، استفاده شوند؛ البته چنین کاربردی هنوز اجرایی نشده و برای انجام اکثر این فعالیتها هنوز از هستههای کودا استفاده میشود. قابلیت DLSS در آینده رشد بیشتری پیدا خواهد کرد.
هستههای تنسور میتوانند پس از اعمال قابلیت رهگیری پرتو در صحنههای بازی، به شیوههای موثری به افزایش میزان فریمریت بازی کمک کنند. همچنین طراحان کارتهای گرافیک جیفورس برای هستههای تنسور اهداف دیگری نیز دارند که از میان آنها میتوان به بهرهگیری از آنها برای پویانمایی بهتر شخصیتهای بازی و شبیهسازی لباس اشاره کرد؛ اما نباید این نکته را فراموش کنیم که تا رسیدن به زمانی که صدها بازی از محاسبهگرهای ماتریس اختصاصی خود در پردازندههای گرافیکی بهصورت معمول و متداول استفاده کنند، راه زیادی باقی مانده است.
آینده هستههای تنسور
در حال حاضر هستههای تنسور تنها قطعات کوچک سختافزاری هستند که فقط در تعداد معدودی از کارتهای گرافیک استفاده میشوند. در آینده چه تغییراتی در انتظار هستههای تنسور است؟ به دلیل اینکه انویدیا عملکرد تک هسته تنسور را در معماری امپر به میزان قابلتوجهی بهبود داده، انتظار میرود در آینده کارتهای میانرده و حتی کارتهای گرافیک ارزانقیمت نیز به هسته تنسور مجهز شود.
اگرچه هسته اینتل و AMD در پردازندههای گرافیکی خود از هسته یا هستههای تنسور استفاده نمیکنند، اما شاید در آینده شاهد قطعات سختافزاری مشابهی در پردازندههای گرافیکی این دو شرکت باشیم. AMD سیستمی را برای افزایش وضوح و نمایش بهترین جزئیات فریمهای تکمیل شده پیشنهاد کرده که عملکرد کارت گرافیک را نیز کمی بهبود میدهد؛ بنابراین در حال حاضر AMD استفاده از همین سیستم که مزایای زیادی دارد، اکتفا میکند؛ به عنوان مثال نیازی نیست توسعهدهندگان مبانی این سیستم را در کدهای خود ادغام کنند و تنها با کمی تغییر در درایور اجرا میشود.

همچنین برخی افراد معتقدند فضای خالی و بلااستفاده کارتهای گرافیکی برای افزودن تعداد بیشتری از هستههای سایهزن، باید بهتر مورد استفاده قرار بگیرد. انویدیا در هنگام ساخت تراشههای اقتصادی دارای معماری تورینگ همین رویکرد را دنبال کرد. برخی از کارتهای گرافیک مانند کارت گرافیک GeForce GTX 1650 فاقد هستههای تنسور هستند و در عوض به هستههای سایهزن FB16 مجهز شدهاند.
در نهایت باید خاطرنشان کنیم که برای انجام عملیات GEMM با سرعت بسیار بالا باید یا از تعداد زیادی پردازنده (CPU) چندهستهای یا از پردازنده گرافیکی مجهز به هستههای تنسور استفاده کنید.
منبع : digiato.com
0